- What is Corba?
- Distributed objects, Corba-style
- What is a distributed Corba Object
- Everything is in IDL
- Corba Components: From System Objects to Business Objects
- OMG’s Object Management Architecture
While object-oriented technology has existed for many years, it still has yet to gain wide acceptance in many areas of the software industry. In particular, the application of object-oriented technology to distributed systems is a relatively new practice. This is where Corba enters the picture.
The Common Object Request Broker Architecture (Corba) is the Object Management Group’s answer to the need for interoperability among the rapidly proliferating number of hardware and software products available today. Simply stated, Corba allows applications to communicate with one another no matter where they are located or who has designed them. Corba 1.1 was introduced in 1991 by Object Management Group (OMG) and defined the Interface Definition Language (IDL) and the Application Programming Interfaces (API) that enable client/server object interaction within a specific implementation of an Object Request Broker (ORB). Corba 2.0, adopted in December of 1994, defines true interoperability by specifying how ORBs from different vendors can interoperate.
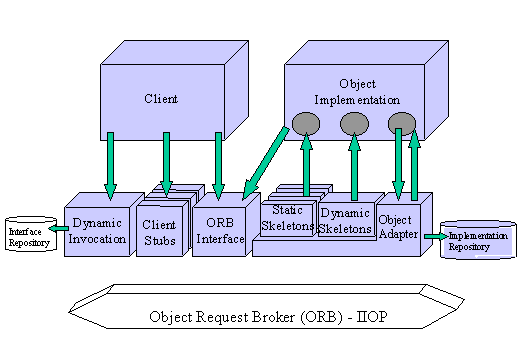
The ORB is the middleware that establishes the client-server relationships between objects. Using an ORB, a client can transparently invoke a method on a server object, which can be on the same machine or across a network. The ORB intercepts the call and is responsible for finding an object that can implement the request, pass it the parameters, invoke its method, and return the results. The client does not have to be aware of where the object is located, its programming language, its operating system, or any other system aspects that are not part of an object’s interface. In so doing, the ORB provides interoperability between applications on different machines in heterogeneous distributed environments and seamlessly interconnects multiple object systems.
In fielding typical client/server applications, developers use their own design or a recognized standard to define the protocol to be used between the devices. Protocol definition depends on the implementation language, network transport and a dozen other factors. ORBs simplify this process. With an ORB, the protocol is defined through the application interfaces via a single implementation language-independent specification, the IDL. And ORBs provide flexibility. They let programmers choose the most appropriate operating system, execution environment and even programming language to use for each component of a system under construction. More importantly, they allow the integration of existing components. In an ORB-based solution, developers simply model the legacy component using the same IDL they use for creating new objects, then write " wrapper " code that translates between the standardized bus and the legacy interfaces.
Corba is a signal step on the road to object-oriented standardization and interoperability. With Corba, users gain access to information transparently, without them having to know what software or hardware platform it resides on or where it is located on an enterprise network. Being the communications heart of object-oriented systems, Corba brings true interoperability to today’s computing environment.
Perhaps the secret to OMG’s success is that it creates interface specifications, not code. The interfaces it specifies are always derived from demonstrated technology submitted by member companies. The specifications are written in the neutral IDL that defines a component’s boundaries—that is, its contractual interfaces with potential clients. Components written to IDL should be portable across languages, tools, operating systems, and networks. And with the adoption of the Corba 2.0 specification in December 1994, these components should be able to interoperate across multi-vendor Corba object brokers.
Corba objects are blobs of intelligence that can live anywhere on a network. They are packaged as binary components that remote clients can access via method invocations. Both the language and compiler used to create server objects are totally transparent to clients. Clients do not need to know where the distributed object resides or what operating system it executes on. It can be in the same process or on a machine that sits across an intergalactic network. In addition, clients do not need to know how the server object is implemented. For example, a server object could be implemented as a set of C++ classes, or it could be implemented with a million lines of existing Cobol code—the client does not even know the difference. What the client needs to know is the interface its server object publishes. This interface serves as a binding contract between clients and servers.
As we said earlier, Corba uses IDL contracts to specify a component’s boundaries and its contractual interfaces with potential clients. The Corba IDL is purely declarative. This means that it provides no implementation details. We can use IDL to define APIs concisely, and it covers important issues such as error handling. IDL-specified methods can be written in and invoked from any language that provides Corba bindings—currently, C, C++, Ada, Smalltalk, Cobol, and Java. Programmers deal with Corba objects using native language constructs. IDL provides operating system and programming language independent interfaces to all the services and components that reside on a Corba bus. It allows client and server objects written in different languages to interoperate, as shown in Figure 1.

Figure 1: Corba IDL Language Bindings Provide Client/Server Interoperability
We can use the OMG IDL to specify the component’s attributes, the parent classes it inherits from, the exceptions it raises, the typed events it emits, and the methods its interface supports—including the input and output parameters and their data types. The IDL grammar is a subset of C++ with additional keywords to support distributed concepts; it also fully supports standard C++ preprocessing features and pragmas.
Notice that we have been using the terms " components " and " distributed objects " interchangeably. Corba distributed objects are, by definition, components because of the way they are packaged. In distributed object systems, the unit of work and distribution is a component. The Corba distributed object infrastructure makes it easier for components to be more autonomous, self-managing, and collaborative. This undertaking is much more ambitious than anything attempted by competing forms of middleware. Corba’s distributed object technology allows us to put together complex client/server information systems by simply assembling and extending components. We can modify objects without affecting the rest of the components in the rest of the system or how they interact. A client/server application becomes a collection of collaborating components. In addition, Corba is incorporating many elements of the JavaBeans component model, which should help make Corba components more " toolable ".